 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Velocity Deficit: Initial Energy Injection for Flow Matching
May 14, 2026While Flow Matching theoretically guarantees constant-velocity trajectories, we identify a critical breakdown in high-dimensional practice: the Velocity Deficit. We show that the MSE objective systematically underestimates velocity magnitude, causing generated samples to fail to reach the data manifold-a phenomenon we term Integration Lag. To rectify this, we propose Initial Energy Injection, instantiated via two complementary methods: the training-based Magnitude-Aware Flow Matching (MAFM) and the training-free Scale Schedule Corrector (SSC). Both are grounded in our discovery of a crucial asymmetry: velocity contraction causes harmful kinetic stagnation at the trajectory's start, yet acts as a beneficial denoising mechanism at its end. Empirically, SSC yields significant efficiency gains with zero retraining and just one line of code. On ImageNet-1k (256x256), it improves FID by 44.6% (from 13.68 to 7.58) and achieves a 5x speedup, enabling a 50-step generator (FID 7.58) to beat a 250-step baseline (FID 8.65). Furthermore, our methods generalize to Text-to-Image tasks and high-resolution generation, improving FID on MS-COCO by ~22%.
Think, then Score: Decoupled Reasoning and Scoring for Video Reward Modeling
May 07, 2026Recent advances in generative video models are increasingly driven by post-training and test-time scaling, both of which critically depend on the quality of video reward models (RMs). An ideal reward model should predict accurate rewards that align with human preferences across diverse scenarios. However, existing paradigms face a fundamental dilemma: \textit{Discriminative RMs} regress rewards directly on features extracted by multimodal large language models (MLLMs) without explicit reasoning, making them prone to shortcut learning and heavily reliant on massive data scaling for generalization. In contrast, \textit{Generative RMs} with Chain-of-Thought (CoT) reasoning exhibit superior interpretability and generalization potential, as they leverage fine-grained semantic supervision to internalize the rationales behind human preferences. However, they suffer from inherent optimization bottlenecks due to the coupling of reasoning and scoring within a single autoregressive inference chain. To harness the generalization benefits of CoT reasoning while mitigating the training instability of coupled reasoning and scoring, we introduce DeScore, a training-efficient and generalizable video reward model. DeScore employs a decoupled ``think-then-score'' paradigm: an MLLM first generates an explicit CoT, followed by a dedicated discriminative scoring module consisting of a learnable query token and a regression head that predicts the final reward. DeScore is optimized via a two-stage framework: (1) a discriminative cold start incorporating a random mask mechanism to ensure robust scoring capabilities, and (2) a dual-objective reinforcement learning stage that independently refines CoT reasoning quality and calibrates the final reward, ensuring that higher-quality reasoning directly translates to superior model performance.
GARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Scaling Image and Video Generation via Test-Time Evolutionary Search
May 23, 2025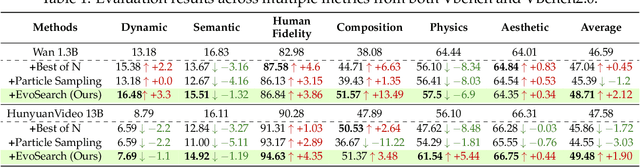

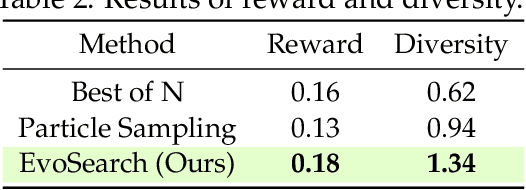
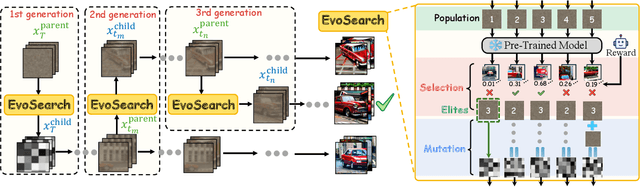
As the marginal cost of scaling computation (data and parameters) during model pre-training continues to increase substantially, test-time scaling (TTS) has emerged as a promising direction for improving generative model performance by allocating additional computation at inference time. While TTS has demonstrated significant success across multiple language tasks, there remains a notable gap in understanding the test-time scaling behaviors of image and video generative models (diffusion-based or flow-based models). Although recent works have initiated exploration into inference-time strategies for vision tasks, these approaches face critical limitations: being constrained to task-specific domains, exhibiting poor scalability, or falling into reward over-optimization that sacrifices sample diversity. In this paper, we propose \textbf{Evo}lutionary \textbf{Search} (EvoSearch), a novel, generalist, and efficient TTS method that effectively enhances the scalability of both image and video generation across diffusion and flow models, without requiring additional training or model expansion. EvoSearch reformulates test-time scaling for diffusion and flow models as an evolutionary search problem, leveraging principles from biological evolution to efficiently explore and refine the denoising trajectory. By incorporating carefully designed selection and mutation mechanisms tailored to the stochastic differential equation denoising process, EvoSearch iteratively generates higher-quality offspring while preserving population diversity. Through extensive evaluation across both diffusion and flow architectures for image and video generation tasks, we demonstrate that our method consistently outperforms existing approaches, achieves higher diversity, and shows strong generalizability to unseen evaluation metrics. Our project is available at the website https://tinnerhrhe.github.io/evosearch.
Flow-GRPO: Training Flow Matching Models via Online RL
May 08, 2025



We propose Flow-GRPO, the first method integrating online reinforcement learning (RL) into flow matching models. Our approach uses two key strategies: (1) an ODE-to-SDE conversion that transforms a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) that matches the original model's marginal distribution at all timesteps, enabling statistical sampling for RL exploration; and (2) a Denoising Reduction strategy that reduces training denoising steps while retaining the original inference timestep number, significantly improving sampling efficiency without performance degradation. Empirically, Flow-GRPO is effective across multiple text-to-image tasks. For complex compositions, RL-tuned SD3.5 generates nearly perfect object counts, spatial relations, and fine-grained attributes, boosting GenEval accuracy from $63\%$ to $95\%$. In visual text rendering, its accuracy improves from $59\%$ to $92\%$, significantly enhancing text generation. Flow-GRPO also achieves substantial gains in human preference alignment. Notably, little to no reward hacking occurred, meaning rewards did not increase at the cost of image quality or diversity, and both remained stable in our experiments.
Asymmetric Decision-Making in Online Knowledge Distillation:Unifying Consensus and Divergence
Mar 09, 2025



Online Knowledge Distillation (OKD) methods streamline the distillation training process into a single stage, eliminating the need for knowledge transfer from a pretrained teacher network to a more compact student network. This paper presents an innovative approach to leverage intermediate spatial representations. Our analysis of the intermediate features from both teacher and student models reveals two pivotal insights: (1) the similar features between students and teachers are predominantly focused on foreground objects. (2) teacher models emphasize foreground objects more than students. Building on these findings, we propose Asymmetric Decision-Making (ADM) to enhance feature consensus learning for student models while continuously promoting feature diversity in teacher models. Specifically, Consensus Learning for student models prioritizes spatial features with high consensus relative to teacher models. Conversely, Divergence Learning for teacher models highlights spatial features with lower similarity compared to student models, indicating superior performance by teacher models in these regions. Consequently, ADM facilitates the student models to catch up with the feature learning process of the teacher models. Extensive experiments demonstrate that ADM consistently surpasses existing OKD methods across various online knowledge distillation settings and also achieves superior results when applied to offline knowledge distillation, semantic segmentation and diffusion distillation tasks.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

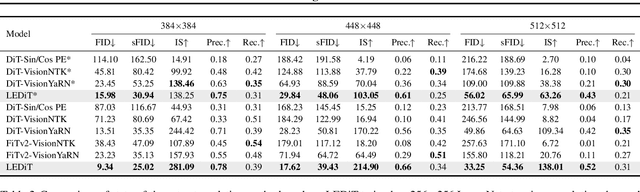

Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Optimizing Knowledge Distillation in Transformers: Enabling Multi-Head Attention without Alignment Barriers
Feb 11, 2025Knowledge distillation (KD) in transformers often faces challenges due to misalignment in the number of attention heads between teacher and student models. Existing methods either require identical head counts or introduce projectors to bridge dimensional gaps, limiting flexibility and efficiency. We propose Squeezing-Heads Distillation (SHD), a novel approach that enables seamless knowledge transfer between models with varying head counts by compressing multi-head attention maps via efficient linear approximation. Unlike prior work, SHD eliminates alignment barriers without additional parameters or architectural modifications. Our method dynamically approximates the combined effect of multiple teacher heads into fewer student heads, preserving fine-grained attention patterns while reducing redundancy. Experiments across language (LLaMA, GPT) and vision (DiT, MDT) generative and vision (DeiT) discriminative tasks demonstrate SHD's effectiveness: it outperforms logit-based and feature-alignment KD baselines, achieving state-of-the-art results in image classification, image generation language fine-tuning, and language pre-training. The key innovations of flexible head compression, projector-free design, and linear-time complexity make SHD a versatile and scalable solution for distilling modern transformers. This work bridges a critical gap in KD, enabling efficient deployment of compact models without compromising performance.